Valuable Insights from "VEO3 Ads + Mobile Apps = F*** You Money" by Alim Charaniya

In this enlightening video, Alim Charaniya breaks down his successful strategies for user-generated content (UGC) ads using Google V3. Here are the key insights and actionable advice from his talk that can transform your ad campaigns.
Key Points to Note
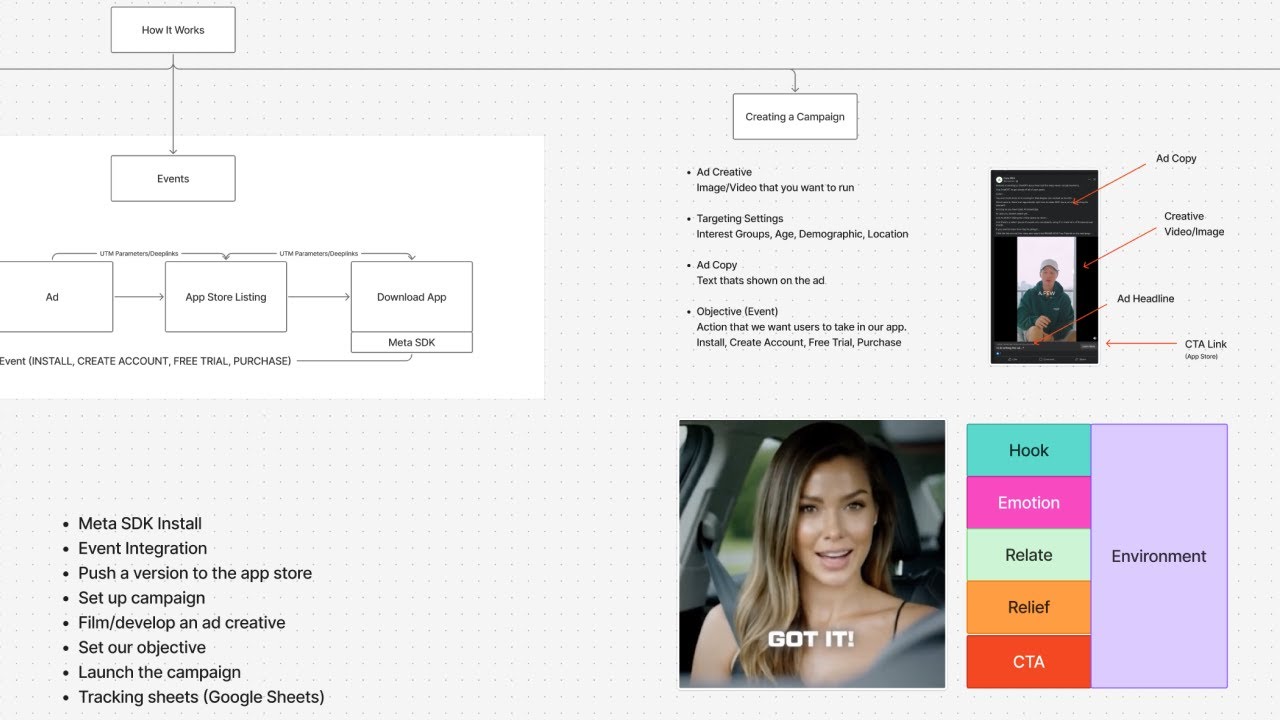
- Campaign Success: Charaniya achieved app downloads at $347 each while maintaining a profitable funnel through UGC ads.
- Human Connection in Ads: Personalization is key; "people buy from people" and trust is crucial in a saturated market.
- Ideal Customer Profile (ICP): Clearly define your ICP, including demographics, problems, emotional states, and context.
- Ad Architecture: Ads should connect with the target audience's feelings, regardless of aesthetics.
Valuable Insights
- Personalize Software Engagement: Creating a personal touch can lead to more effective marketing strategies.
- Focus on Emotional Appeal: Successful ads focus on one core emotion (fear, relief, ambition) for better tracking of ad performance.
- Target Wealthy Customers: Direct your messaging towards affluent individuals more likely to invest in your app.
Actionable Steps to Implement
- Identify and Define Your ICP: Clarify who your ideal customer is, including motivations, frustrations, and lifestyle.
- Use ChatGPT for Ad Ideas: Leverage AI tools to brainstorm tailored ads focusing on emotional levers.
- Construct Ads with Cohesion: Ensure alignment among the ad environment, language, and actors to resonate with your target audience.
- Iterate and Test: Launch multiple ad versions targeting different ICPs to find the most effective segments.
Supporting Details
- Charaniya provided a targeted ad example for solar salespeople addressing common objections, enhancing relatability.
- Ads must maintain visual and emotional cohesion, employing actors that the audience can identify with.
Personal Reflections
The content presented aligns with essential marketing strategies focused on understanding the customer. In today's competitive market, deeper emotional connections and personalization are paramount for standing out. Charaniya's insights into leveraging AI for marketing reflect the evolving trends, enabling targeted and efficient marketing practices.
Conclusion
This concise analysis covers crucial themes, insights, and strategies to improve ad campaigns with a focus on the emotional and personal aspects of marketing today. For a detailed understanding, you can watch Alim Charaniya's full video:
Follow us on our journey to learn more about marketing and technology! Connect with me on social media: